Intro To SQLAlchemy - GormAnalysis¶
Intro¶
Every week or so I get an idea for an app. Most of them are pretty dumb. For example, “slot market” - an app that looks like a slot machine. You put up a dollar, pull a virtual level, and then the app buys $1 of a random stock, sells it a second later, and returns your profit / loss.
But every once in a while I get an idea I really like. Rather than hire someone to build all my ideas, I’ve taken up learning Python FastAPI so I can build them myself. However, FastAPI depends heavily on SQLAlchemy (well, not technically but for all intents and purposes it does). Unfortunately, SQLAlchemy is confusing. There’s a lot of “magic” that happens under the hood. There’s a spider web system of sessions, connections, engines, and models. Should I autocommit? What’s the difference between flushing and committing? How do I create the database in the first place??
A few days ago, I bit the bullet and sledged through the SQLAlchemy docs. I ran some experiments and did a lot of googling, and finally wrapped my head around SQLAlchemy (I think). In this article, I document my understanding of SQLAlchemy; mostly for my future self when I inevitably forget how it works.
Motivation¶
Let’s get motivated. Let’s design a database to support a recreational beach volleyball complex. (If you’re wondering, yes, I play.) Our complex has leagues like “Fall 2021” and “Spring 2022”. Each league has a collection of teams like “Safe Sets” and “The Empire Spikes Back”. And of course, each league has games like “Safe Sets vs The Empire Spikes Back”. Naturally, we’ll want to build three relational tables like the following.
leagues
id |
name |
|---|---|
1 |
Fall 2021 |
2 |
Spring 2022 |
teams
id |
league_id |
name |
|---|---|---|
1 |
1 |
Safe Sets |
2 |
1 |
The Empire Spikes Back |
3 |
2 |
Ace Holes |
4 |
2 |
The Empire Spikes Back |
5 |
2 |
Beaches and Holes |
6 |
2 |
How I Set Your Mother |
games
id |
home_team_id |
away_team_id |
|---|---|---|
1 |
1 |
2 |
2 |
2 |
1 |
3 |
3 |
1 |
4 |
6 |
5 |
5 |
4 |
6 |
Setup¶
To get started, I’ll install SQLAlchemy using
pip install sqlalchemy. Note that I’m using version
1.4.26 on top of Python 3.9.7. Also, I’m using
PyCharm as my IDE.
Database Initialization¶
How do you create a new database? Well, it depends on what
type of database you want to create. For our purposes, we’ll
just create a SQLite database which is entirely contained
within a single file, usually with a .db or .sqlite
extension. Here are two ways to do that.
Use the
sqlalchemy-utilspackage. (pip install sqlalchemy-utils)
from sqlalchemy_utils import create_database
create_database('sqlite+pysqlite:///vball.db')
This creates an empty file named vball.db in the same
directory from which you execute this code.
Alternatively, create the database file yourself, manually. It’s literally just an empty file with a
.dbextension. You can either runtouch vball.dbfrom the terminal / command line or right click on the folder of your project > new file > vball.db. Most IDEs will support something like this.
Connecting To The Datbaase¶
Now that we’ve initialized a SQLite database, how do we connect to it? Well, like this
from sqlalchemy import create_engine
engine = create_engine("sqlite+pysqlite:///vball.db", future=True)
Here we create an engine, a necessary first step for connecting SQLAlchemy to a database.
"qlite+pysqlite:///vball.db" is the database URL. In
general, it takes the form
"dialect+driver://username:password@host:port/database".
Accordingly, our engine can figure out that our Dialect is
sqlite, our driver is pysqlite and our database is
hosted on our local machine at /vball.db. A production
database URL would look more like
"postgresql://ryan:smith\@190.190.200.100:5432/mydatabase".
I’m sure you’re also wondering what future=True does?
SQLAlchemy made major improvements their internal API in
2020. They migrated from version 1.0 to version 2.0. Rather
than replace their old API, they created the new 2.0 API
alongside it. The future=True flag tells SQLAlchemy to
create the new style engine, not the old style. (If you try
it both ways and inspect type(engine) you can see the
difference.)
Running the code¶
There are two ways you can run this code.
Execute the entire script using the terminal / shell command:
python path/to/main.pyExecute each line in a python console
The nice thing about option 2 is that you can tinker with the objects you create. Here’s what it looks like in PyCharm.
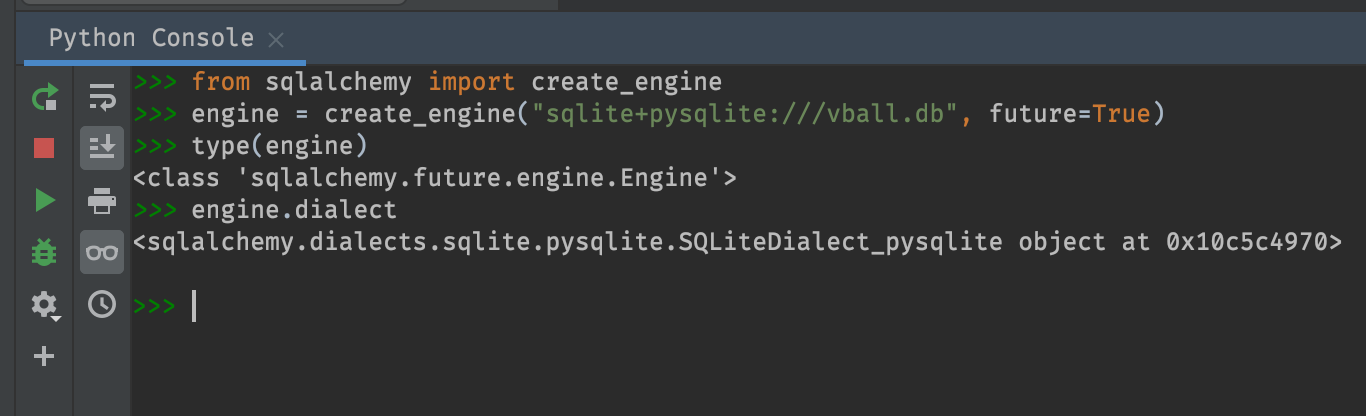
You can see I got curios after creating my engine and checked to see its type and its dialect.
Dialects¶
Keep in mind, there are many different flavors of SQL. PostgreSQL, MySQL, SQLite, … They’re all slightly different in terms of their syntax and functionality. So, not only does SQLAlchemy have to translate your python code into SQL, but it has to translate your python code into the correct flavor of SQL. This why our engine created above carries a Dialect object. It’s like a translator that knows how to talk to all sorts of SQL databases.
Hello World¶
Now let’s execute a simple SQL query:
"SELECT 'hello world'".
from sqlalchemy import create_engine, text
# Make the engine
engine = create_engine("sqlite+pysqlite:///vball.db", future=True)
# Establish a connection
conn = engine.connect()
# Run the query and store the result
result = conn.execute(text("SELECT 'hello world'"))
# Print the result
print(result.all())
# Close the connection
conn.close()
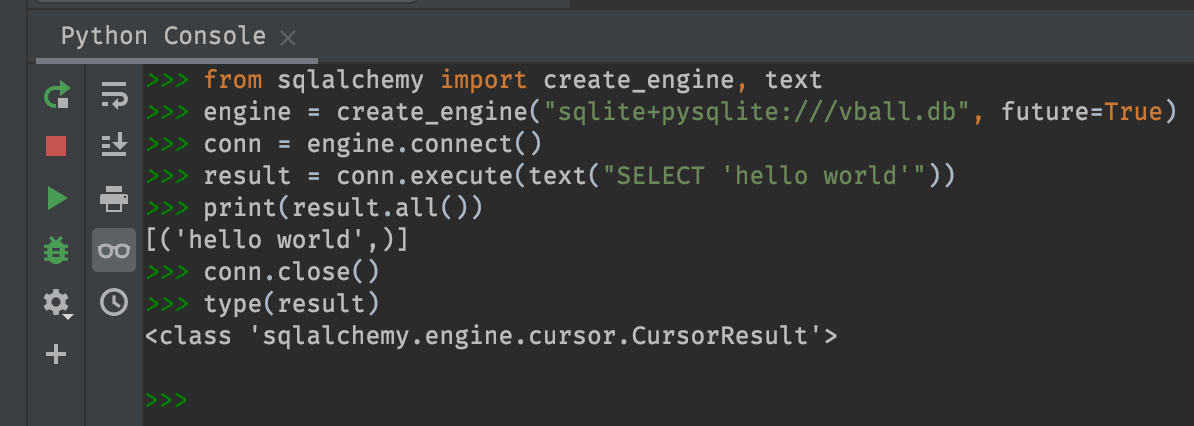
Here we create a connection to the database using the
engine.connect() method. Then we use the
conn.execute() method, passing in
text("SELECT 'hello world'"). The result of this is a
CursorResult object (see type(result)) which we
print via print(result.all()). Then we close our
connection because leaving an open, unused database
connection is bad.
What if our program errored before closing the connection?
Well, the connection would be left open (not good). So, a
better approach would be to wrap our code in a
try finally block like
from sqlalchemy import create_engine, text
# Establish a connection
conn = engine.connect()
try:
# Run the query and store the result
result = conn.execute(text("SELECT 'hello world'"))
# Print the result
print(result.all())
finally:
# Close the connection
conn.close() # <- runs even if an error occurs in the try block
Even if an error occurs during our query, our connection to
the database will close thanks the to finally block. An
easier way to do this is by using a Context Manager via the
with statement, like
from sqlalchemy import create_engine, text
# Make the engine
engine = create_engine("sqlite+pysqlite:///vball.db", future=True)
# Use a context manager
with engine.connect() as conn:
result = conn.execute(text("SELECT 'hello world'"))
print(result.all())
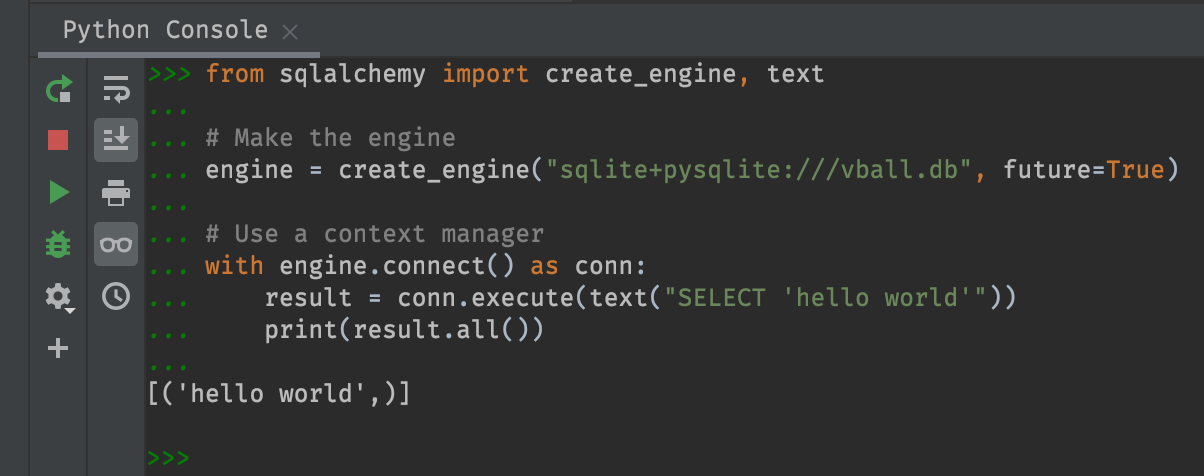
Here the connection is closed automatically when the
with block finishes, and if an error occurs during
execution of the with block, the connection object’s
__exit__() method is invoked which will automatically
close the connection.
Let’s peek under the hood a bit more.. We’ll run the same
code as above, except we’ll initialize the engine with the
echo=True flag.
from sqlalchemy import create_engine, text
# Make the engine
engine = create_engine("sqlite+pysqlite:///vball.db", future=True, echo=True)
# Use a context manager
with engine.connect() as conn:
result = conn.execute(text("SELECT 'hello world'"))
print(result.all())
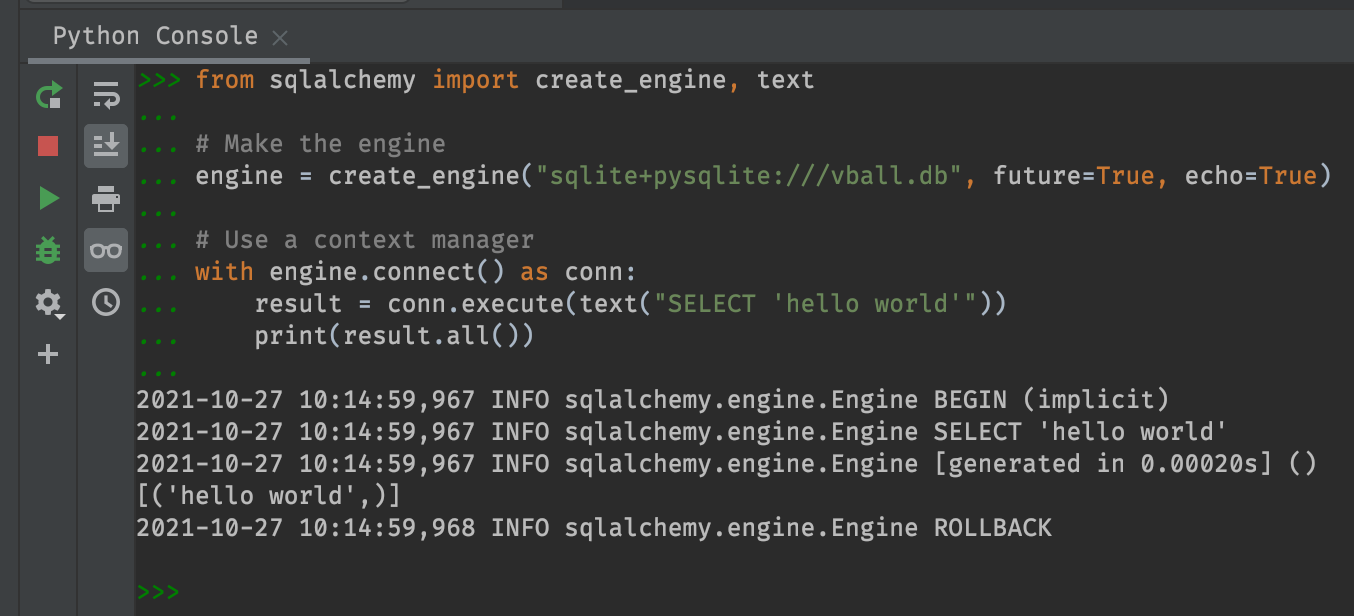
Using echo=True tells SQLAlchemy to print the SQL code
it sends to the database, to the console. Here we can see
that even though we just told it to execute the SQL
statement “SELECT ‘hello world’” it actually did more than
that.. It executed three lines, namely
BEGIN (implicit)
SELECT 'hello world'
ROLLBACK
I’ll explain what this means in a little bit. But now let’s
focus on the result. I stated earlier that result is
a CursorResult object. What that means is, it’s a
pointer to the query result which lives in the SQL
database. We don’t actually fetch the result from the
database until do something like result.all().
Suppose we placed print(result.all()) outside of the
context manager, like this
from sqlalchemy import create_engine, text
# Make the engine
engine = create_engine("sqlite+pysqlite:///vball.db", future=True, echo=True)
# Use a context manager
with engine.connect() as conn:
result = conn.execute(text("SELECT 'hello world'"))
print(result.all())
What do you think will happen?
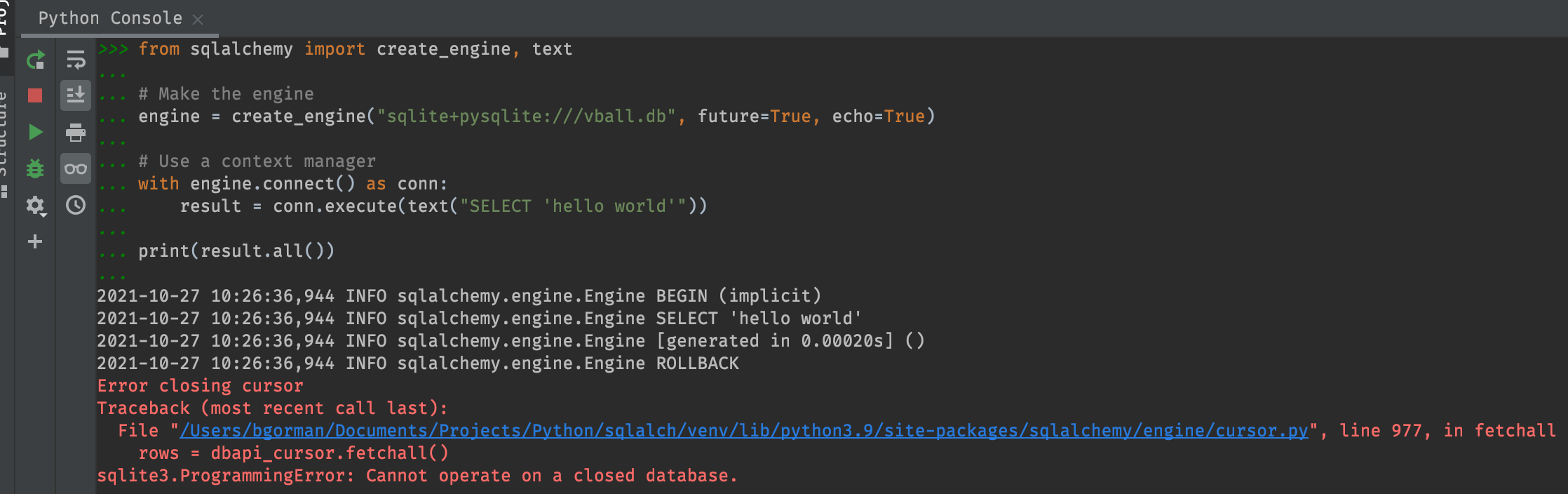
In this case we get an error:
sqlite3.ProgrammingError: Cannot operate on a closed database..
Again, result just a pointer that tells us where to
fetch the result of our query, but to actually fetch the
result we need an open database connection. So, if you want
to use the data outside the context manager (after the
connection is closed), you’d need to store the result to a
variable within the context manager, while the connection is
still open.
Creating A Table¶
Let’s make a SQL table called leagues.
from sqlalchemy import create_engine, text
# Make the engine
engine = create_engine("sqlite+pysqlite:///vball.db", future=True, echo=True)
# Define the SQL string
strSQL = "CREATE TABLE leagues (id INTEGER PRIMARY KEY, name VARCHAR(255));"
# Use a context manager
with engine.connect() as conn:
conn.execute(text(strSQL))
Now if you open vball.db in a basic text editor
(e.g. TextEdit on mac), you’ll see something like this

It’s slightly cryptic, but you can tell our leagues table
was successfully created. Another way to see it is to
install the handy TablePlus
app, and then open the
vball.db file with TablePlus.
Notice that we created our leagues table with two fields:
id, an auto-incrementing integer field designated as the primary keyname, a VARCHAR (string) field
Inserting data¶
Now let’s insert some data.
from sqlalchemy import create_engine, text
# Make the engine
engine = create_engine("sqlite+pysqlite:///vball.db", future=True, echo=True)
# Define SQL strings
strSQLCreate = "CREATE TABLE leagues (id INTEGER PRIMARY KEY, name VARCHAR(255));"
strSQLInsert = "INSERT INTO leagues (name) VALUES ('Summer 2022')"
# Use a context manager
with engine.connect() as conn:
conn.execute(text(strSQLCreate))
conn.execute(text(strSQLInsert))
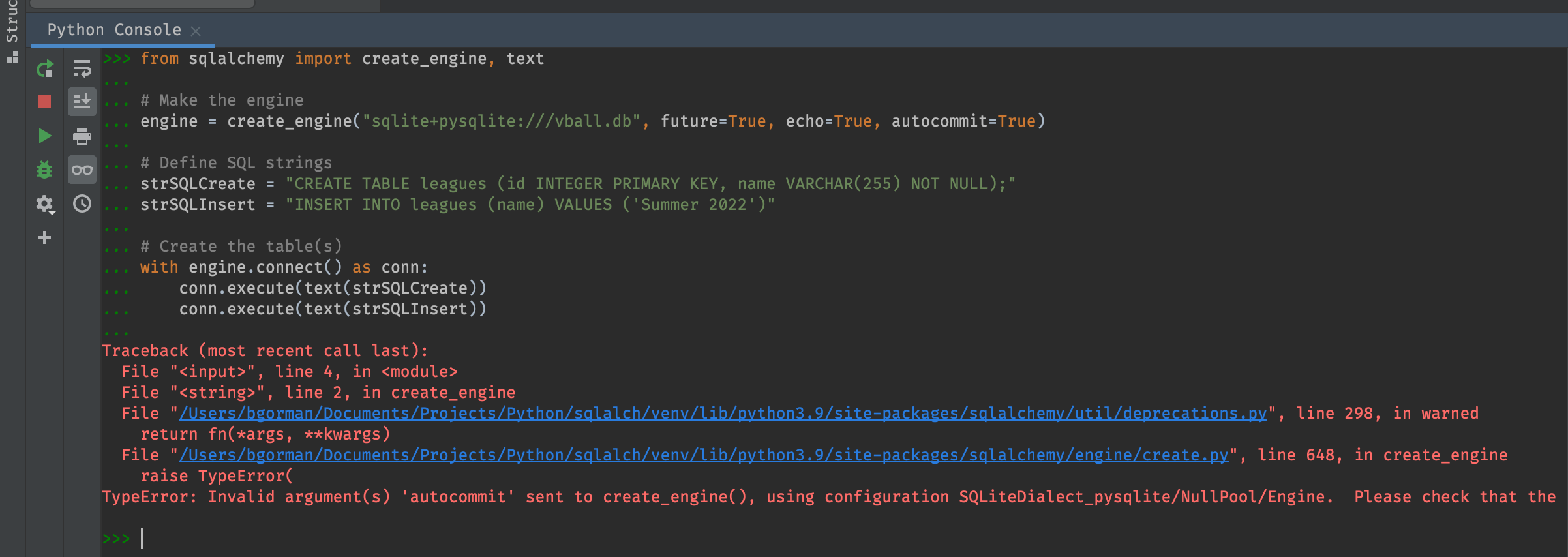
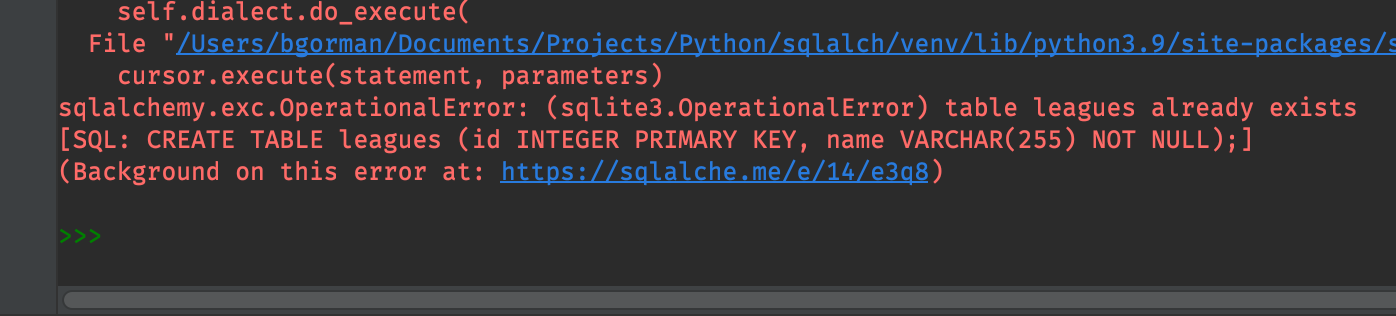
If you’re following along, you should get an error like “table leagues already exists”. Ooops. We have a few options here
Comment out the line that attempts to create the table
Delete the database file before running this code
Convert our sqlite database to an in-memory database
I’ll go with option three. It’s a convenient and clear way to iterate through tests and ideas.
In-Memory Database¶
To create an in-memory SQLite database, all we have to do is change
engine = create_engine("sqlite+pysqlite:///vball.db", future=True, echo=True)
to
engine = create_engine("sqlite+pysqlite:///:memory:", future=True, echo=True)
Now the database will live inside the Python session. So, when the session ends, the database gets deleted.
Inserting data (Attempt 2)¶
Let’s try that again..
from sqlalchemy import create_engine, text
# Make the engine
engine = create_engine("sqlite+pysqlite:///:memory:", future=True, echo=True)
# Define SQL strings
strSQLCreate = "CREATE TABLE leagues (id INTEGER PRIMARY KEY, name VARCHAR(255));"
strSQLInsert = "INSERT INTO leagues (name) VALUES ('Summer 2022')"
# Create the table(s)
with engine.connect() as conn:
conn.execute(text(strSQLCreate))
# Insert rows
with engine.connect() as conn:
conn.execute(text(strSQLInsert))
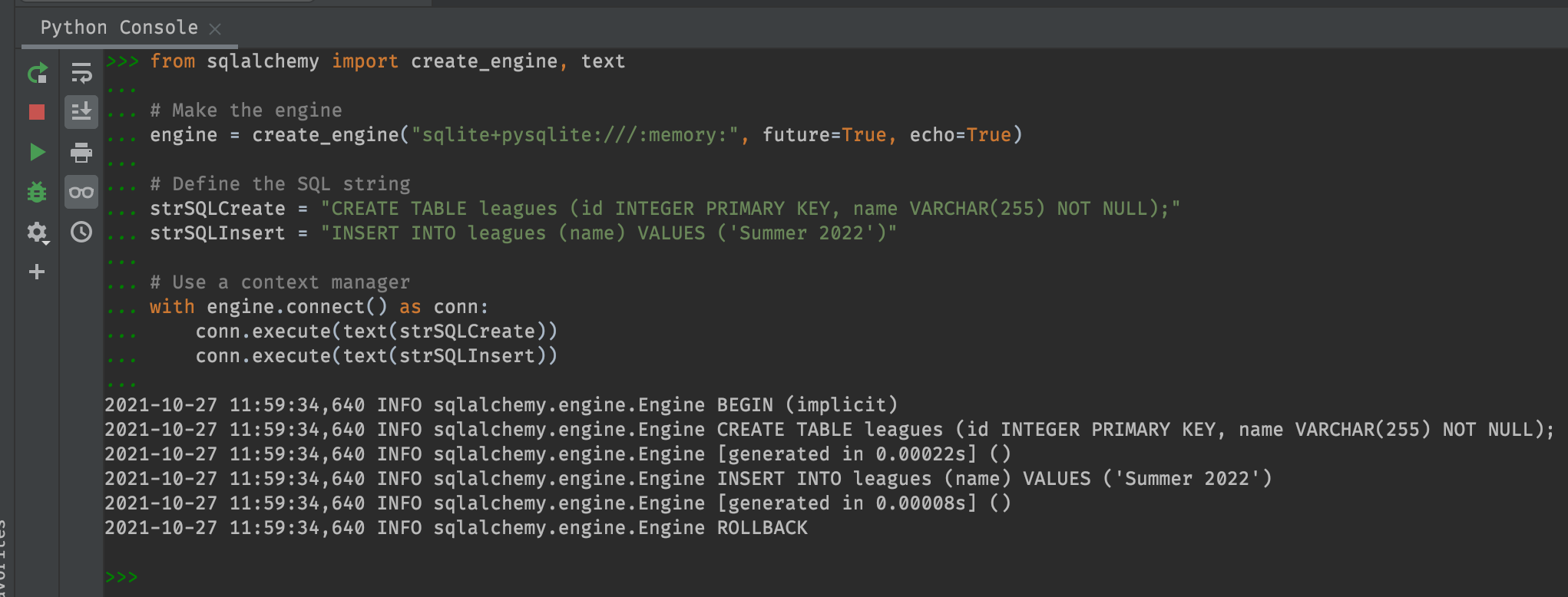
Well, it runs without error this time.. To see if it worked, let’s tack on a “SELECT * FROM leagues” query..
from sqlalchemy import create_engine, text
# Make the engine
engine = create_engine("sqlite+pysqlite:///:memory:", future=True, echo=True)
# Define SQL strings
strSQLCreate = "CREATE TABLE leagues (id INTEGER PRIMARY KEY, name VARCHAR(255));"
strSQLInsert = "INSERT INTO leagues (name) VALUES ('Summer 2022')"
strSQLCheck = "SELECT * FROM leagues"
# Create the table(s)
with engine.connect() as conn:
conn.execute(text(strSQLCreate))
# Insert rows and check
with engine.connect() as conn:
conn.execute(text(strSQLInsert))
result = conn.execute(text(strSQLCheck))
print(result.all())
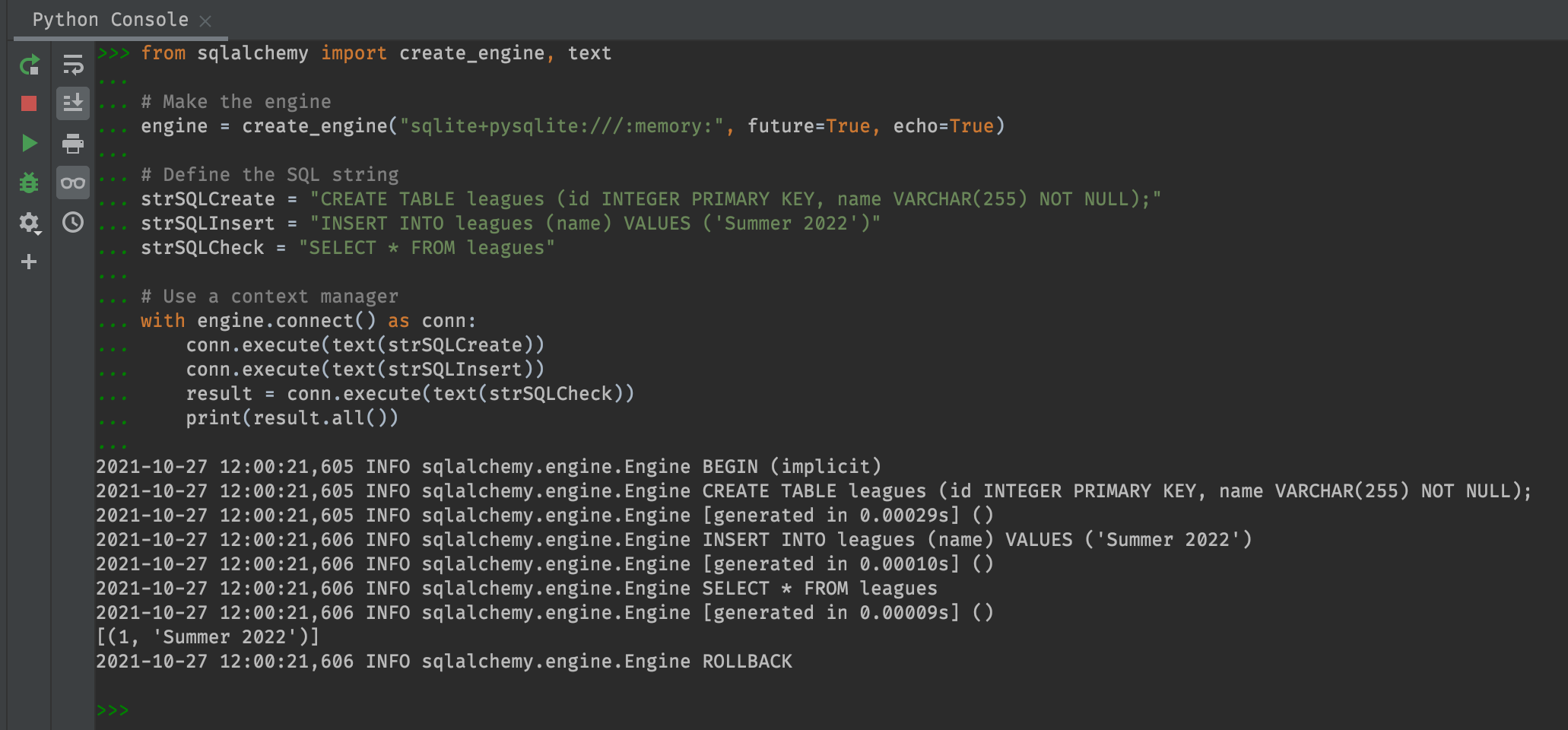
It worked! Or did it.. Let’s try that again, this time
placing the "SELECT * FROM leagues" query in a
subsequent connection object / context manager.
from sqlalchemy import create_engine, text
# Make the engine
engine = create_engine("sqlite+pysqlite:///:memory:", future=True, echo=True)
# Define SQL strings
strSQLCreate = "CREATE TABLE leagues (id INTEGER PRIMARY KEY, name VARCHAR(255));"
strSQLInsert = "INSERT INTO leagues (name) VALUES ('Summer 2022')"
strSQLCheck = "SELECT * FROM leagues"
# Create the table(s)
with engine.connect() as conn:
conn.execute(text(strSQLCreate))
# Insert rows
with engine.connect() as conn:
conn.execute(text(strSQLInsert))
# Check result
with engine.connect() as conn:
result = conn.execute(text(strSQLCheck))
print(result.all())
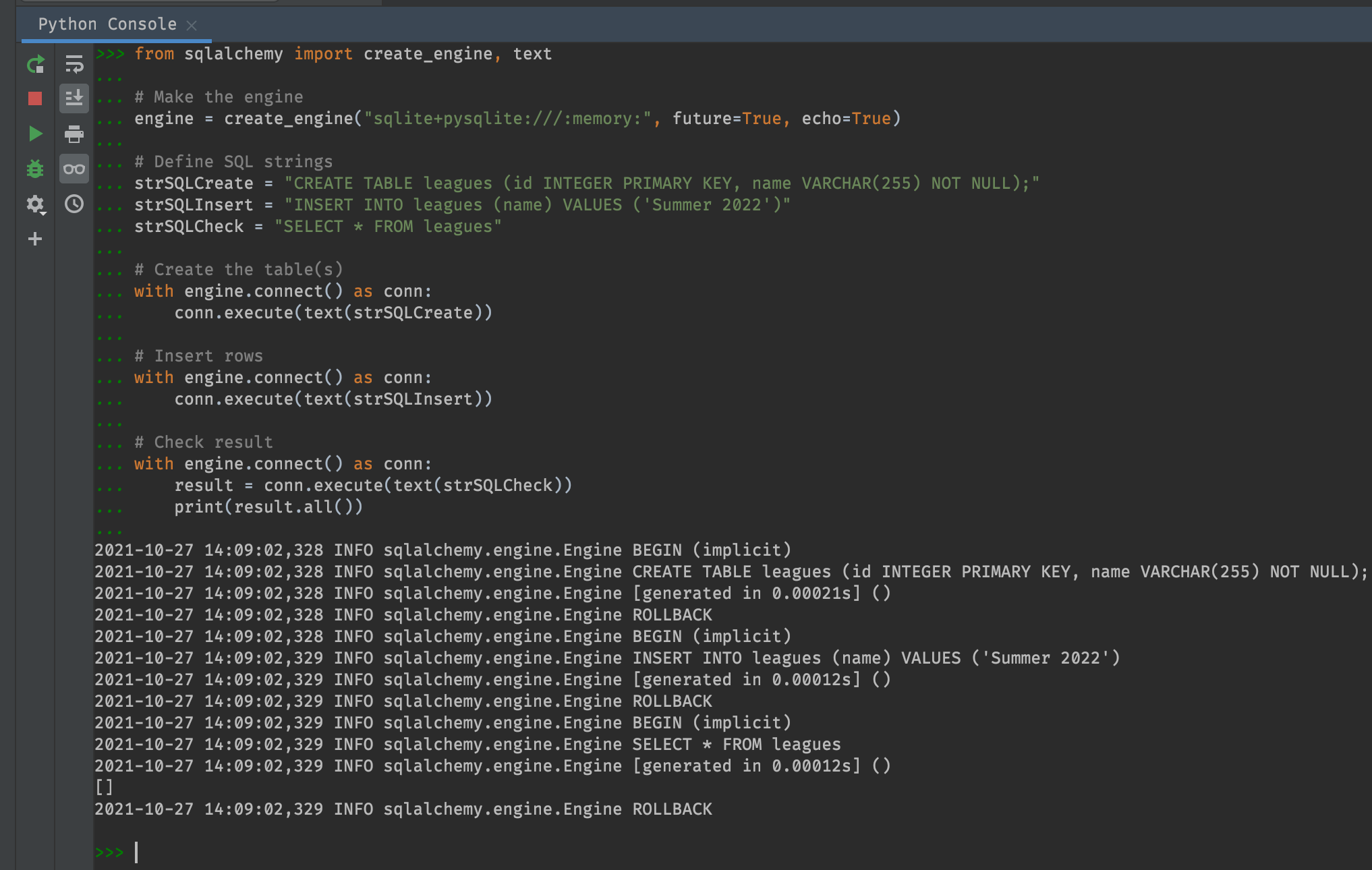
Hmm, this time the result is empty! What gives?? The
explanation has to do with that auto-generated ROLLBACK
statement we’ve been ignoring…
ROLLBACK vs COMMIT¶
Sometimes you want to execute multiple SQL statements and have them succeed or fail as a whole. For example, if we want to transfer money from account A into account B, we need to do two operations like
UPDATE accounts SET value = value - 100 WHERE acct = 'A'
UPDATE accounts SET value = value + 100 WHERE acct = 'B'
If the first operation succeeds, but the second operation fails, that’s bad. I mean that’s really bad. So, if any of these operations fail, we want them all to fail.
We should tell the database that these two SQL statements
are part of a single “transaction”. But how? Well, we’ll
start every transaction with BEGIN and end every
transaction with either ROLLBACK or COMMIT.
BEGIN
UPDATE accounts SET value = value - 100 WHERE acct = 'A'
UPDATE accounts SET value = value + 100 WHERE acct = 'B'
COMMIT
Now it’s clear to the database that theses statements are part of a single transaction, and they should succeed or fail as a whole. Partial success is not acceptable.
What’s interesting about this is, the database actually
carries out every SQL statement. It doesn’t wait around
for a COMMIT / ROLLBACK statement to alter the data.
This is why our example above appeared to work until we put
the “SELECT *” statement into a different context manager.
In the original example, we queried the table after data was
inserted but before the database encountered the
ROLLBACK statement and reversed the INSERT.
So, when a transaction ends with a ROLLBACK statement,
the database literally has to undo everything it did in the
transaction. How does it know how to undo a transaction, you
ask? Well the database maintains a log of every operation
which looks like
logs
transaction_id |
timestamp |
operation |
|---|---|---|
3947 |
2021-11-01 22:59:53Z |
BEGIN |
3947 |
2021-11-01 22:59:55Z |
UPDATE accounts SET value = value - 100 WHERE acct = ‘A’ |
3947 |
2021-11-01 22:59:58Z |
UPDATE accounts SET value = value + 100 WHERE acct = ‘B’ |
3947 |
2021-11-01 22:59:59Z |
ROLLBACK |
Thanks to these logs, the database knows exactly how to undo a transaction.
Now, by default, if we don’t manually issue a COMMIT or
ROLLBACK before closing our connection, SQLAlchemy will
issue a ROLLBACK. If you want the connection object to
automatically issue a COMMIT before closing, you can do
something like
with engine.connect().execution_options(autocommit=True) as conn:
# your code here
but I think it’s better to leave the default ROLLBACK as
is. Manually COMMIT your changes to confirm they’re good
and you want them to persist. For example, like this
from sqlalchemy import create_engine, text
# Make the engine
engine = create_engine("sqlite+pysqlite:///:memory:", future=True, echo=True)
# Define SQL strings
strSQLCreate = "CREATE TABLE leagues (id INTEGER PRIMARY KEY, name VARCHAR(255));"
strSQLInsert = "INSERT INTO leagues (name) VALUES ('Summer 2022')"
strSQLCheck = "SELECT * FROM leagues"
# Create the table(s)
with engine.connect() as conn:
conn.execute(text(strSQLCreate))
# Insert rows
with engine.connect() as conn:
conn.execute(text(strSQLInsert))
conn.commit()
# Check result
with engine.connect() as conn:
result = conn.execute(text(strSQLCheck))
print(result.all())
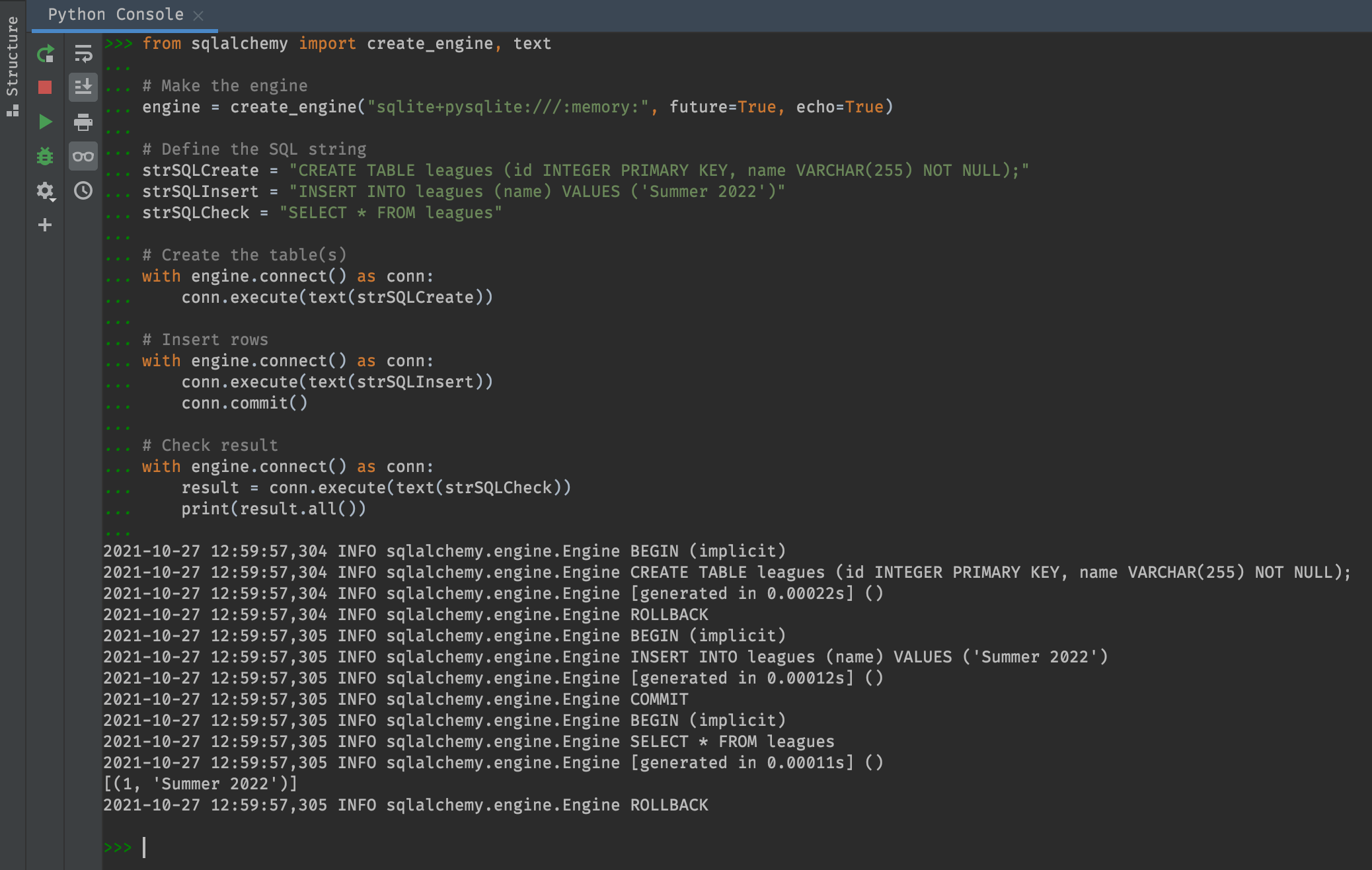
Here you can see the data persists even after we close the connection used to insert data.
Hold on a sec.. We created the leagues table with a
SQL statement that was followed by ROLLBACK. Why did the
table persist? Well, in most cases the table would
rollback, and we’d notice an error when we attempt to insert
data into the non-existent table. BUT, it turns out that
the default Python driver for SQLite automatically commits
DDL statements
(things like CREATE TABLE, ALTER TABLE,
DROP TABLE, etc.).
Data Validation / Constraints¶
WARNING. Users will try to destroy your data by inputting trash. You must block said trash at all costs. The last line of defense to prevent bad data from entering your database is the database itself. In our case, some useful constraints we should consider are
Make sure every league name non null.
Make sure every league name is unique.
Make sure every league_id in the teams table is non null. (Every team must be associated with a league)
Make sure every team name is non null.
Make sure every (league_id, team name) is unique. (A league can’t have two teams with the same name)
Make sure the foreign keys home_team_id and away_team_id in our games table are non null. (Every game should be tied to two teams)
Make sure foreign keys home_team_id and away_team_id in our games table are different (A team cannot play itself)
Let’s recreate our leagues table, this time adding the
NON NULL flag to the name field, to prevent someone
from creating a league without a name.
from sqlalchemy import create_engine, text
# Make the engine
engine = create_engine("sqlite+pysqlite:///:memory:", future=True, echo=True)
# Define SQL strings
strSQLCreate = "CREATE TABLE leagues (id INTEGER PRIMARY KEY, name VARCHAR(255) NOT NULL);"
strSQLInsert = "INSERT INTO leagues (name) VALUES (NULL)"
# Create the table(s)
with engine.connect() as conn:
conn.execute(text(strSQLCreate))
# Insert rows
with engine.connect() as conn:
conn.execute(text(strSQLInsert))
conn.commit()
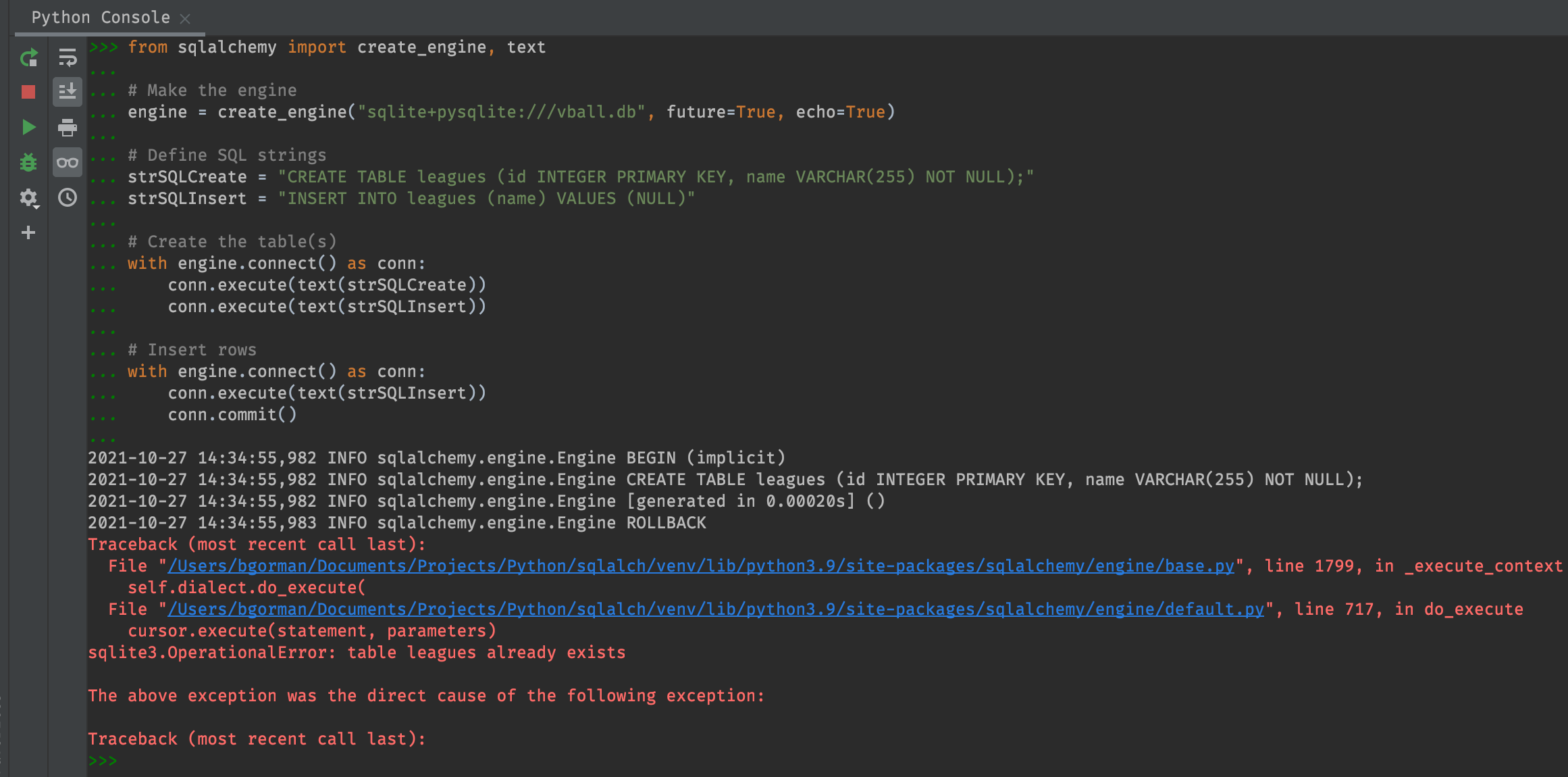
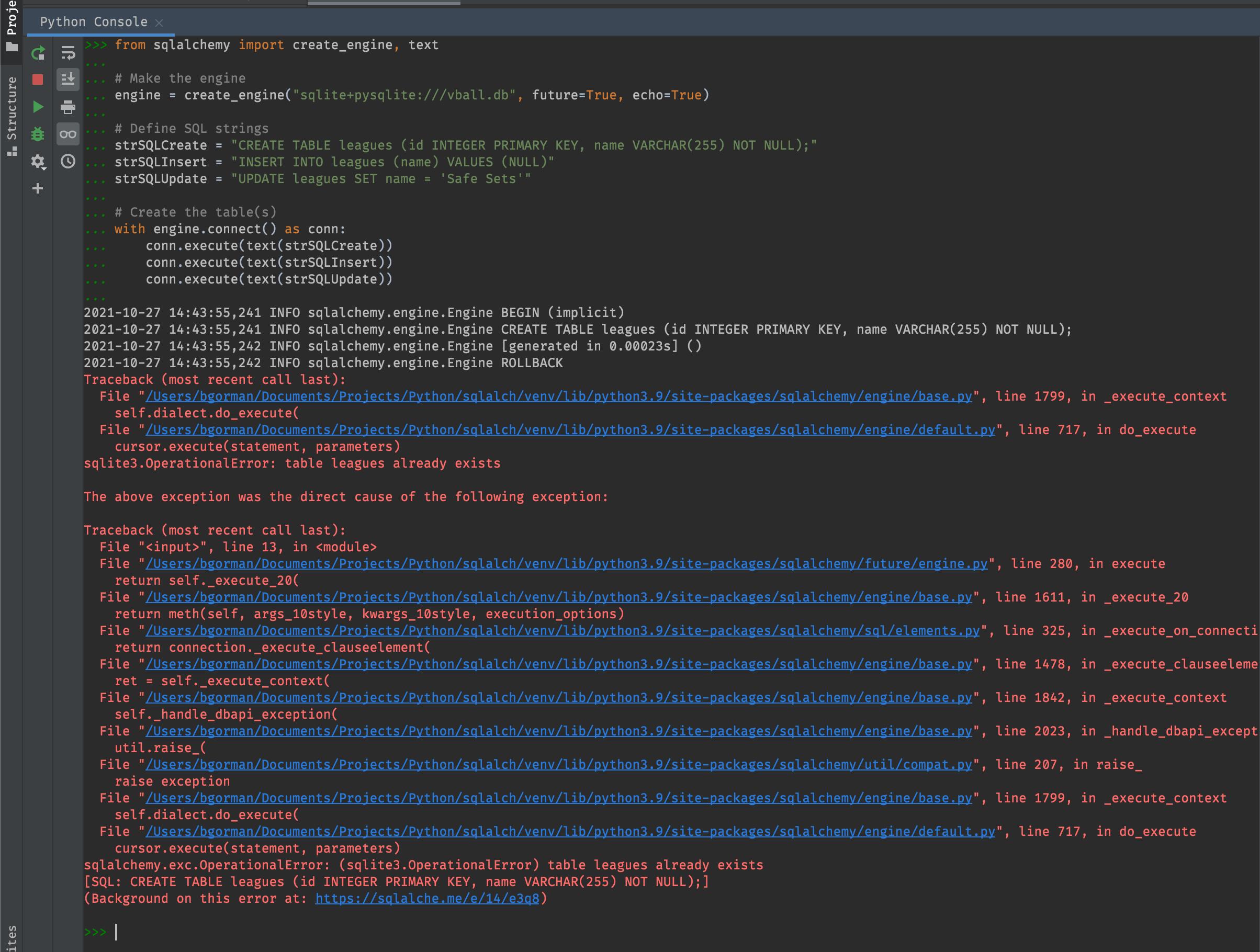
Brilliant! Our NON NULL constraint prevented us from inserting a row with a NULL name value. This brings up an interesting question.. Is the constrain enforced after every SQL operation or at the end of every SQL transaction? For example, what if we create a transaction like
BEGIN
INSERT INTO leagues (name) VALUES (NULL)
UPDATE leagues SET name = 'Safe Sets'
COMMIT
Does this violate the non-null constraint, raising an error? Turns out, yes it does.
If you’d rather the database wait until the end of each transaction before checking for constraint violations, you might be able to set that up using a DEFERRED constraint, depending on your database.
Locks¶
There’s one more thing we should consider before we discuss SQLALchemy’s ORM.. In a production setting, you could have dozens of users making changes to your database at the same time. This is referred to as concurrency. So, what happens if two users try to modify the same record around the same exact time? For example, consider a scenario where user1 inserts a new league and user2 attempts to modify that league before user1 commits the insert?
from sqlalchemy import create_engine, text
# Make the engine
engine = create_engine("sqlite+pysqlite:///vball.db", future=True, echo=True)
# Do stuff
with engine.connect() as conn1, engine.connect() as conn2:
conn1.execute(text("CREATE TABLE leagues (id INTEGER PRIMARY KEY, name VARCHAR(255) NOT NULL);"))
conn1.execute(text("INSERT INTO leagues (name) VALUES ('Safe Sets')"))
conn2.execute(text("UPDATE leagues SET name = 'Dumpster Fire'"))
conn1.commit()
conn2.commit()
result = conn2.execute(text("SELECT name FROM leagues"))
print(result.all())
NOTE SQLAlchemy + SQLite in-memory database does something weird (funnels all connection objects through a single connection), so in this example I’m using a SQLite file saved to disc.
The code above results in an error, “database is locked”.
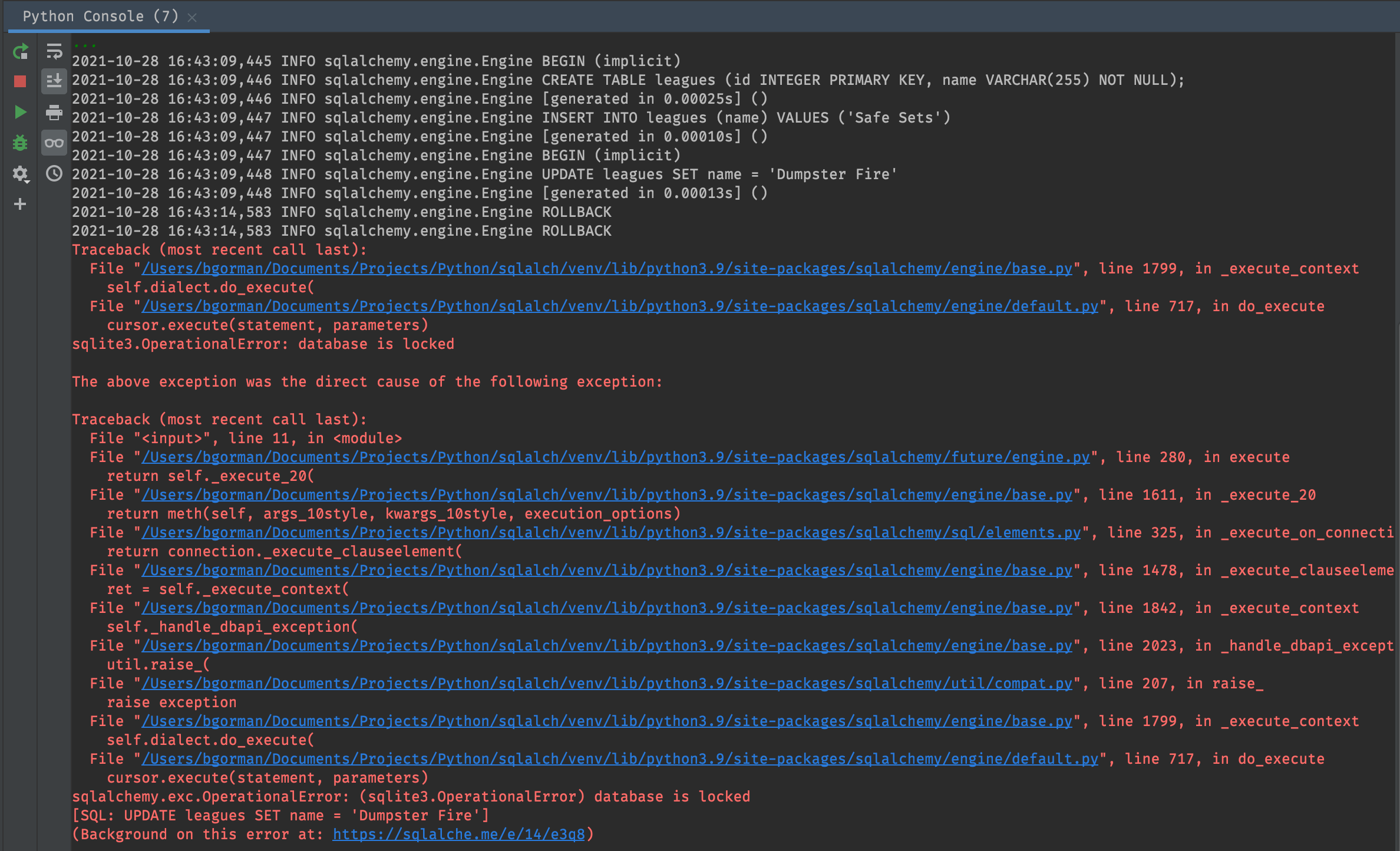
A database lock occurs when someone has modified data, but
they haven’t finished their transaction with a COMMIT or
ROLLBACK. In this case, conn1 inserted data, and
then conn2 tried to modify that data before conn1
committed the insert, so the database raised an error.
Database locks can be placed on a row, a column, a table, or even a whole database. They can be “shared” (people can read the data but not overwrite it) or “exclusive” (people can’t read or write the data). And different databases handle locks differently.
I don’t want to delve into the gritty details of locks, but they’re something you should be aware of, especially if your database has multiple users or clients requesting and modifying data at the same time.
ORM¶
So far, we’ve been creating our leagues table by writing out the SQL CREATE statement and then sending that SQL to the database. We inserted new rows into the table by doing basically the same thing - writing out SQL INSERT statements and then sending them to the database to be executed.
You could imagine it would be useful to have a Python
League class. Then we could make League instances to use
within our application code and reference things like
league.name and league.teams. I mean, wouldn’t it be
nicer to update a league’s name via
league.name = "Block Party"
as opposed to
UPDATE leagues SET name = 'Block Party' WHERE id = 1
SQLAlchemy’s ORM (Object-Relational Mapping) makes this possible!
Now, you can imagine the challenges that come with managing an ORM. Particularly, how does it keep Python objects and database records “in sync”? Fortunately, most of the complexities are handled under the hood by SQLAlchemy, but there are a few things to be aware of..
Table Declaration¶
“Just make the damn tables already!” Okay, okay.. We’ll start by building a League class / leagues table.
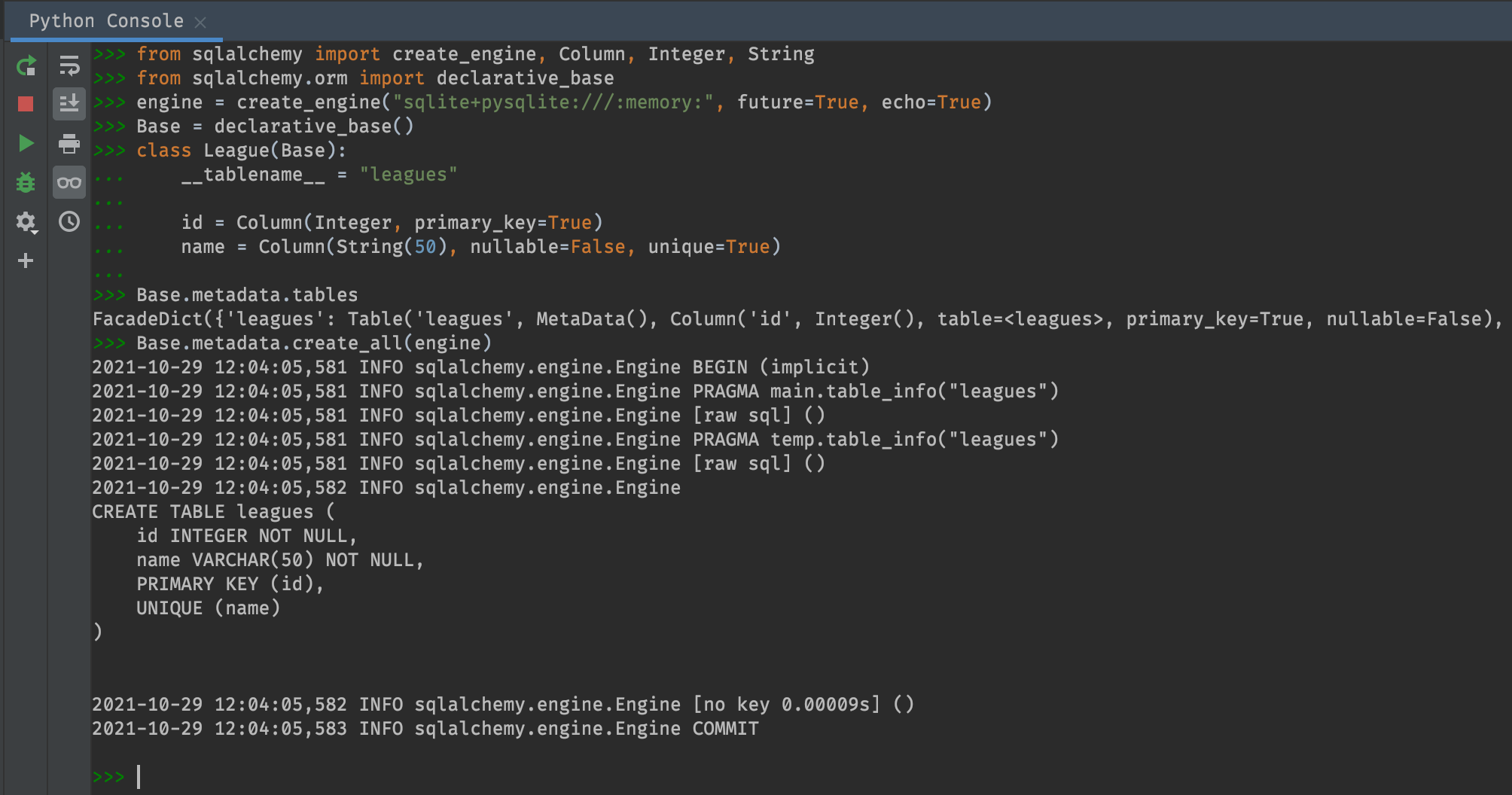
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.orm import declarative_base
# Make the engine
engine = create_engine("sqlite+pysqlite:///:memory:", future=True, echo=True)
# Make the DeclarativeMeta
# This is a base class meant to be inherited.
# It carries a MetaData (Base.metadata) and a registry (Base.registry)
Base = declarative_base()
# Declare Classes / Tables
class League(Base):
__tablename__ = "leagues"
id = Column(Integer, primary_key=True)
name = Column(String(50), nullable=False, unique=True)
# Base's metadata now "knows about" leagues
Base.metadata.tables
# Create the tables in the database
Base.metadata.create_all(engine)
Let me explain.. So you want to build a League class to use in your application code, eh? Then you’d expect to do something like
class League():
__tablename__ = "leagues"
id = Column(Integer, primary_key=True)
name = Column(String(50), nullable=False, unique=True)
The thing is, SQLAlchemy has no idea this League class is
something you want to include in its ORM. In other words,
SQLAlchemy needs to maintain a mapping of
Python Class <-> SQL Table like
Python Class |
SQL Table |
|---|---|
League |
leagues |
Team |
teams |
Game |
games |
There are a few ways to do this, but to make the process as
painless as possible, SQLAlchemy has something called a
DeclarativeMeta. A DeclarativeMeta is a base class. It’s
meant to be inherited by other classes, which is exactly
what we do when we declare the League class like
League(Base). Let’s revisit the steps.
Base = declarative_base()declarative_base()is a factory function that returns a “DeclarativeMeta” class. So,Baseis a DeclarativeMeta class, intended to be subclassed.Class Leage(Base):Leagueis a class that inherits fromBase. So, it gets all the goodies provided byBaseandBase“knows about”League.
The League class itself is fairly self-explanatory..
__tablename__ = "leagues"states that theLeagueclass should correspond to a SQL table named “leagues”.id = Column(Integer, primary_key=True)setsidas an integer primary key. (It’s also auto-incrementing by default.)name = Column(String(50), nullable=False, unique=True)sets anamefield as a String with 50 characters or less. Additionally, we force it to be Non NULL and unique.
SQLAlchemy provides lots of options for customizing fields.
To create the table, we call
Base.metadata.create_all(engine). You can see the DDL
statement issued to the database in the picture above.
Inserting Data¶
Okay, how do we insert a new record into the leagues table?
Create a new League instance
# Create a league instance
league = League(name='Ace Holes')
Create a new Session
# Create a new session
from sqlalchemy.orm import Session
session = Session(bind=engine)
Insert the league
session.add(league)
session.commit()
session.close()
The new kid on the block here is Session..
Session¶
The Session we create above is responsible for syncing the Python objects we add to it with the corresponding database records. It handles connecting to the database and executing SQL queries. For example, consider the following
# Create a new session
from sqlalchemy.orm import Session
session = Session(bind=engine, autoflush=True)
# Create a league instance
myleague = League(name='Hitting Bricks')
print(myleague.id)
# Add league to the session, then commit
session.add(myleague)
session.commit()
# Check the id
print(myleague.id)
# Close the session
session.close()
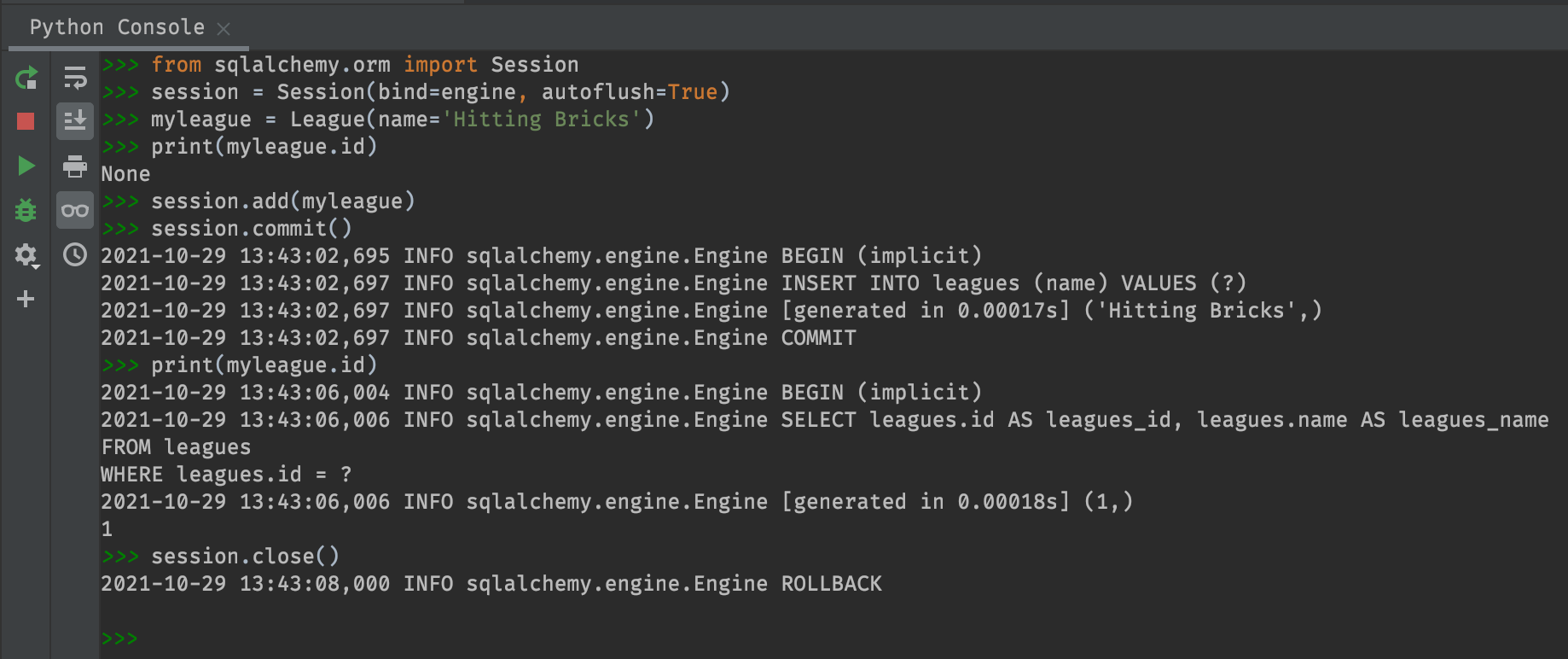
Right after we initialize myleague, its id attribute
is None. But once we add it to the session and commit the
session, myleague.id returns “1”. That’s because the
myleague Python instance corresponds to the first record
in the leagues table of the database. The Session is
responsible for keeping track of that. Also notice that when
we print(myleague.id) the second time, the session
actually queries the database.
Let’s test our understanding a bit..
from sqlalchemy.orm import Session
session = Session(bind=engine, autoflush=True)
myleague = League(name='Hitting Bricks')
session.add(myleague)
session.commit()
myleague.name = "Setting Ducks"
session.close()
# What will this print?
print(myleague.name)
This prints out “Setting Ducks” BUT the database has the
league with name “Hitting Bricks”, because we didn’t
actually commit the change to league.name. Okay how
about this one..
from sqlalchemy.orm import Session
session = Session(bind=engine, autoflush=True)
myleague = League(name='Hitting Bricks')
session.add(myleague)
session.commit()
myleague.name = "Setting Ducks"
# What will this print?
print(session.execute("SELECT name from leagues where id = 1").all())
# What will this print?
print(myleague.name)
session.close()
The first print statement shows “Hitting Bricks” and the second print statement shows “Setting Ducks”. Okay one more..
from sqlalchemy.orm import Session
session = Session(bind=engine, autoflush=True)
myleague = League(name='Hitting Bricks')
session.add(myleague)
session.commit()
myleague.name = "Setting Ducks"
# Flush the data
session.flush()
# What will this print?
print(session.execute("SELECT name from leagues where id = 1").all())
# What will this print?
print(myleague.name)
session.close()
with Session(bind=engine) as session2:
# What will this print?
print(session.execute("SELECT name from leagues where id = 1").all())
This time we see “Setting Ducks”, “Setting Ducks”, “Hitting Bricks”. In this case, we flushed the session, but we didn’t commit it.
Flush vs Commit¶
Sessions keep track of changes to the objects inside them. When an object is changed, there are two steps to update the database to reflect those changes.
You flush the session. This executes the necessary SQL to update the database
You commit the session. This sends a COMMIT statement. It tells the database our transaction is final and should persist.
Alternatively, after you flush the data, you can
session.rollback() which will undo the SQL statements
that were flushed to the database. It’s the same concept we
discussed earlier regarding database transactions.
Relationships¶
Let’s build the teams and games tables we’ve been putting off.
from sqlalchemy import create_engine, Column, Integer, String, ForeignKey, UniqueConstraint, CheckConstraint
from sqlalchemy.orm import declarative_base
# Make the engine
engine = create_engine("sqlite+pysqlite:///:memory:", future=True, echo=True)
# Make the DeclarativeMeta
Base = declarative_base()
# Declare Classes / Tables
class League(Base):
__tablename__ = "leagues"
id = Column(Integer, primary_key=True)
name = Column(String(50), nullable=False, unique=True)
class Team(Base):
__tablename__ = "teams"
__table_args__ = (UniqueConstraint('league_id', 'name', name='_league_team_uc'),)
id = Column(Integer, primary_key=True)
name = Column(String(50), nullable=False)
league_id = Column(Integer, ForeignKey('leagues.id'), nullable=False)
class Game(Base):
__tablename__ = "games"
__table_args__ = (CheckConstraint('home_team_id <> away_team_id', name='_different_teams_cc'),)
id = Column(Integer, primary_key=True)
home_team_id = Column(Integer, ForeignKey('teams.id'), nullable=False)
away_team_id = Column(Integer, ForeignKey('teams.id'), nullable=False)
# Create the tables in the database
Base.metadata.create_all(engine)
The declaration of our classes / tables (which are often called database models) is fairly straightforward. Now if we want to insert a league with two teams and a single game, we can do something like this
from sqlalchemy.orm import Session
# Make a session
session = Session(bind=engine)
# Add a league
league1 = League(name='Summer 2022')
session.add(league1)
session.commit()
# Add teams
team1 = Team(name='Safe Sets', league_id=league1.id)
team2 = Team(name='Hitting Bricks', league_id=league1.id)
session.add(team1)
session.add(team2)
session.commit()
# Add a game
game1 = Game(home_team_id=team1.id, away_team_id=team2.id)
session.add(game1)
session.commit()
What’s lacking here are dynamic relationships between our
models. In our application code, wouldn’t it be sweet if we
could reference league1.teams to fetch a list of all the
teams in a league1? Or team1.games to fetch all the
games involving team1? Or team2.league to fetch the
league tied to team2? SQLAlchemy let’s us set this up by
defining model relationships. For example, to gain the
ability to reference league1.teams, we can do
from sqlalchemy.orm import relationship # <-- add this
# Declare Classes / Tables
class League(Base):
__tablename__ = "leagues"
id = Column(Integer, primary_key=True)
name = Column(String(50), nullable=False, unique=True)
teams = relationship("Team") # <-- add this
Again, we insert data as before (this time with a context manager to automatically close the session)
with Session(bind=engine) as session:
# Add a league
league1 = League(name='Summer 2022')
session.add(league1)
session.commit()
# Add teams
team1 = Team(name='Safe Sets', league_id=league1.id)
team2 = Team(name='Hitting Bricks', league_id=league1.id)
session.add(team1)
session.add(team2)
session.commit()
# Add a game
game1 = Game(home_team_id=team1.id, away_team_id=team2.id)
session.add(game1)
session.commit()
And now we can fetch the league and call league1.teams
# view the league's teams
session = Session(bind=engine)
league1 = session.query(League).get(1)
league1.teams
session.close()
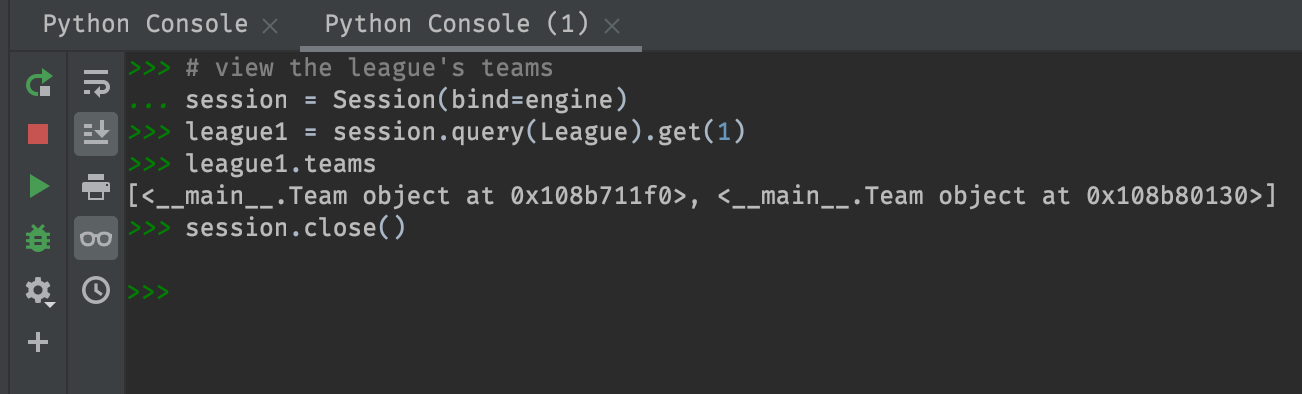
(Here we fetch the league using
league1 = session.query(League).get(1). This is
SQLAlchemy’s Expressive Query Language. More on this in a
bit..)
Cool! Except the resulting list of teams isn’t very
descriptive. If we implement the __repr__() method in
the Team class, we can make the Team objects print to the
console with more descriptive names, like this
class Team(Base):
__tablename__ = "teams"
__table_args__ = (UniqueConstraint('league_id', 'name', name='_league_team_uc'),)
def __repr__(self) -> str:
return f'team with id {self.id}'
id = Column(Integer, primary_key=True)
name = Column(String(50), nullable=False)
league_id = Column(Integer, ForeignKey('leagues.id'), nullable=False)
Now the same call to league1.teams prints out a more
descriptive list.
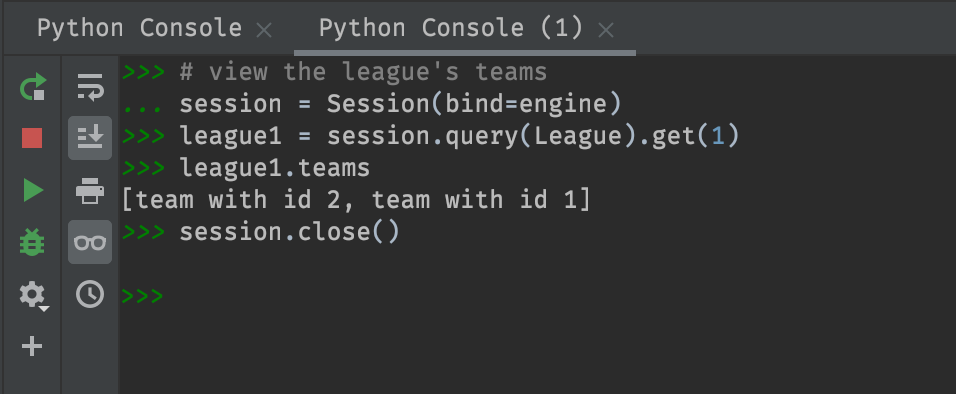
One last note - If you try to insert data and read data using the same session, you might get an error like “SQLite objects created in a thread can only be used in that same thread”. Split the work into multiple Sessions and you should be okay.
Now let’s give Teams the ability to reference their parent League object.
from sqlalchemy import create_engine, Column, Integer, String, ForeignKey, UniqueConstraint, CheckConstraint
from sqlalchemy.orm import declarative_base, relationship
class League(Base):
__tablename__ = "leagues"
def __repr__(self) -> str:
return f'league with id {self.id}'
id = Column(Integer, primary_key=True)
name = Column(String(50), nullable=False, unique=True)
teams = relationship("Team")
class Team(Base):
__tablename__ = "teams"
__table_args__ = (UniqueConstraint('league_id', 'name', name='_league_team_uc'),)
def __repr__(self) -> str:
return f'team with id {self.id}'
id = Column(Integer, primary_key=True)
name = Column(String(50), nullable=False)
league_id = Column(Integer, ForeignKey('leagues.id'), nullable=False)
league = relationship("League")
Now we create a league and a team, and then we append the
team object to the league’s .teams list.
from sqlalchemy.orm import Session
# Make a session
session = Session(bind=engine)
# Add a league
league1 = League(name='Summer 2022')
session.add(league1)
# Add teams
team1 = Team(name='Safe Sets')
session.add(team1)
# Append team1 to league1.teams
league1.teams.append(team1)
# Print league1.teams and team1.league
print(league1.teams) # [team with id None]
print(team1.league) # None
# Close the session
session.close()
Hrmm, we have a problem. team1.league prints None,
but since we added it to league1.teams, it should
print something like "league with id None". It seems
that the team object doesn’t automatically get updated in
this way. Fortunately, SQLAlchemy provides a nice solution
to this via the back_populates parameter of
relationship(). In our case, fix this issue by changing
teams = relationship("Team") to
teams = relationship("Team", back_populates='league')
and league = relationship("League") to
league = relationship("League", back_populates='teams').
Let’s complete our database models so we can move on. Here’s a complete working demo
from sqlalchemy import create_engine, Column, Integer, String, ForeignKey, UniqueConstraint, CheckConstraint
from sqlalchemy.orm import declarative_base, relationship, Session
# Make the engine
engine = create_engine("sqlite+pysqlite:///:memory:", future=True, echo=False)
# Make the DeclarativeMeta
Base = declarative_base()
# Declare Classes / Tables
class League(Base):
__tablename__ = "leagues"
def __repr__(self) -> str:
return f'league with id {self.id}'
id = Column(Integer, primary_key=True)
name = Column(String(50), nullable=False, unique=True)
# relationships
teams = relationship("Team", back_populates='league')
games = relationship("Game",
secondary="teams",
primaryjoin="League.id == Team.league_id",
secondaryjoin="Team.id == Game.home_team_id",
viewonly=True)
class Team(Base):
__tablename__ = "teams"
__table_args__ = (UniqueConstraint('league_id', 'name', name='_league_team_uc'),)
def __repr__(self) -> str:
return f'team with id {self.id}'
id = Column(Integer, primary_key=True)
name = Column(String(50), nullable=False)
league_id = Column(Integer, ForeignKey('leagues.id'), nullable=False)
# relationships
league = relationship("League", back_populates='teams')
games = relationship("Game", primaryjoin="or_(Team.id==Game.home_team_id, "
"Team.id==Game.away_team_id)")
class Game(Base):
__tablename__ = "games"
__table_args__ = (CheckConstraint('home_team_id <> away_team_id', name='_different_teams_cc'),)
def __repr__(self) -> str:
return f'game with id {self.id}'
id = Column(Integer, primary_key=True)
home_team_id = Column(Integer, ForeignKey('teams.id'), nullable=False)
away_team_id = Column(Integer, ForeignKey('teams.id'), nullable=False)
# relationships
home_team = relationship("Team", foreign_keys=home_team_id, back_populates='games')
away_team = relationship("Team", foreign_keys=away_team_id, back_populates='games')
league = relationship("League",
secondary="teams",
primaryjoin="Game.home_team_id == Team.id",
secondaryjoin="Team.league_id == League.id",
viewonly=True)
# Create the tables in the database
Base.metadata.create_all(engine)
# Insert data
with Session(bind=engine) as session:
# Add a league
league1 = League(name='Summer 2022')
session.add(league1)
session.commit()
# Add teams
team1 = Team(name='Safe Sets', league=league1)
team2 = Team(name='Hitting Bricks', league=league1)
session.add(team1)
session.add(team2)
session.commit()
# Add games
game1 = Game(home_team=team1, away_team=team2)
game2 = Game(home_team=team2, away_team=team1)
session.commit()
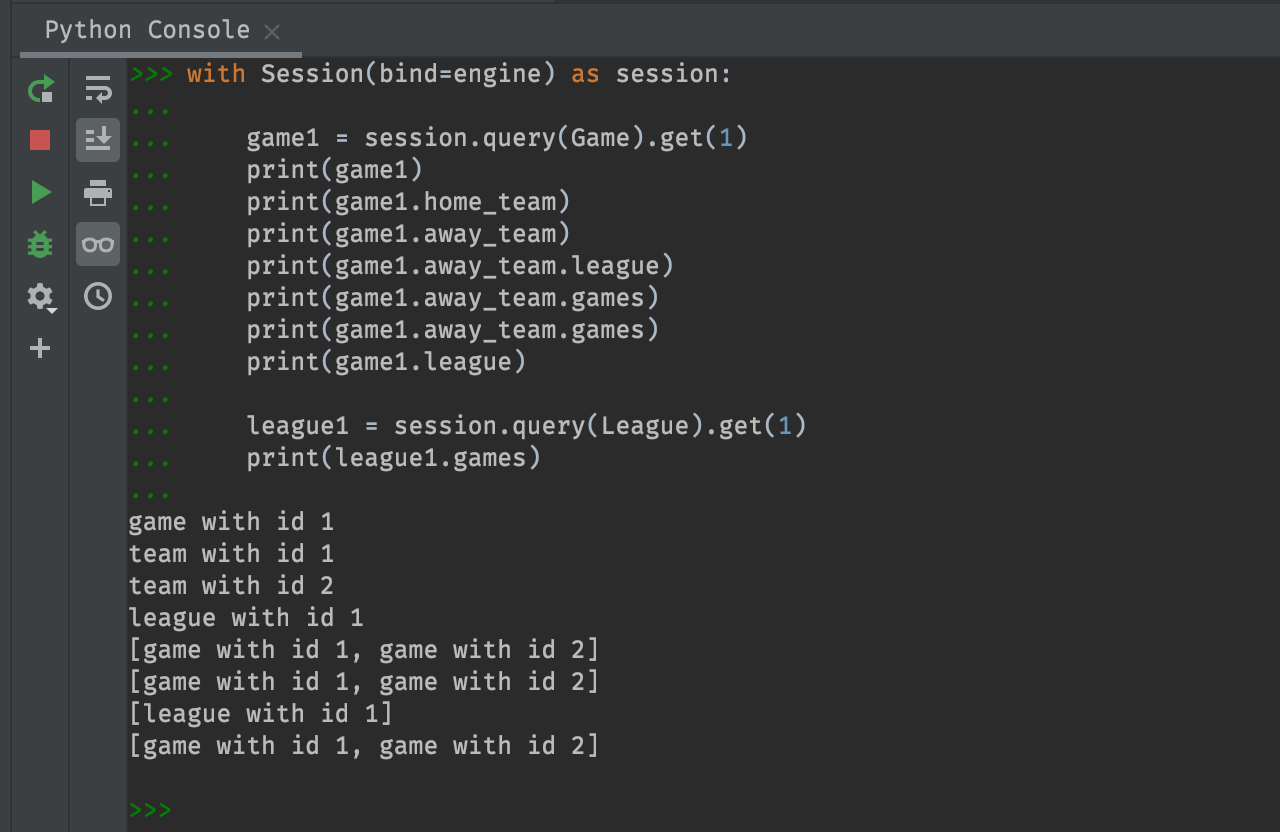
# Read data
with Session(bind=engine) as session:
game1 = session.query(Game).get(1)
print(game1)
print(game1.home_team)
print(game1.away_team)
print(game1.away_team.league)
print(game1.away_team.games)
print(game1.away_team.games)
print(game1.league)
league1 = session.query(League).get(1)
print(league1.games)
Expressive Query Language¶
Once we have data in the database, how do we retrieve it? The best way to learn this is just to work through some examples. We’ll carry on using the data inserted at the end of the previous section.
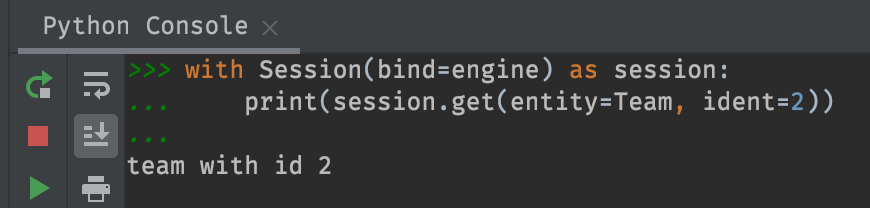
Select the team with id 2
with Session(bind=engine) as session:
print(session.get(entity=Team, ident=2))
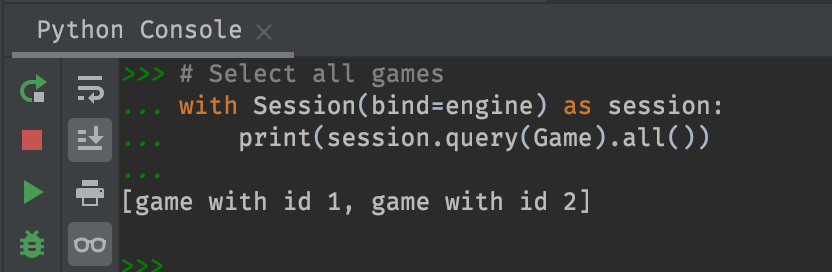
Select all games
with Session(bind=engine) as session:
print(session.query(Game).all())
Select all leagues with a name that contains “Summer”
with Session(bind=engine) as session:
print(session.query(League).filter(League.name.contains('Summer')).all())

Select the first game involving the team with id 1
with Session(bind=engine) as session:
print(session.query(Game).filter((Game.home_team_id == 1) | (Game.away_team_id == 1)).first())

As you can see, SQLAlchemy has its own Expressive Query Language (EQL) which is like its own flavor of SQL. I didn’t go deep here, but you could do pretty much anything your heart desires including joins, groupbys, orderbys, etc.
But, why go through the trouble of learning SQLAlchemy’s EQL when you already know SQL? The answer is portability - and that’s probably the main reason to use SQLAlchemy in the first place. Assuming you use SQLAlchemy’s EQL, you can swap out a MySQL database for a PostgreSQL, and simply by changing your engine’s dialect, your code will work without skipping a beat. You won’t have to refactor MySQL queries into PostgreSQL queries - SQLAlchemy does it for you behind the scenes.
Thoughts¶
I wrote this article for the same reason I write most articles - I didn’t really understand SQLAlchemy and I wanted to learn more about it. Today I see it’s benefits and power much more than I did weeks ago. However, I still feel like there’s much I don’t understand about it, and frankly I’m debating whether the benefits of using SQLAlchemy outweigh its additional complexity to my projects ¯\(ツ)/¯